
SING-SQL: A Synthetic Data Generation Framework for In-Domain Text-to-SQL Translation
October 7, 2025
Overview
SING-SQL is a fully automated, two-stage framework for generating high-quality, high-coverage synthetic Text-to-SQL data for any target database — without relying on SQL logs or manual annotations. The framework partitions schemas hierarchically, synthesizes complexity-controlled SQL paired with natural language, validates with LLM-as-a-judge, checks executability, repairs automatically, and generates reasoning traces. To boost coverage, it balances table-level with column-focused generation so underrepresented attributes are included.
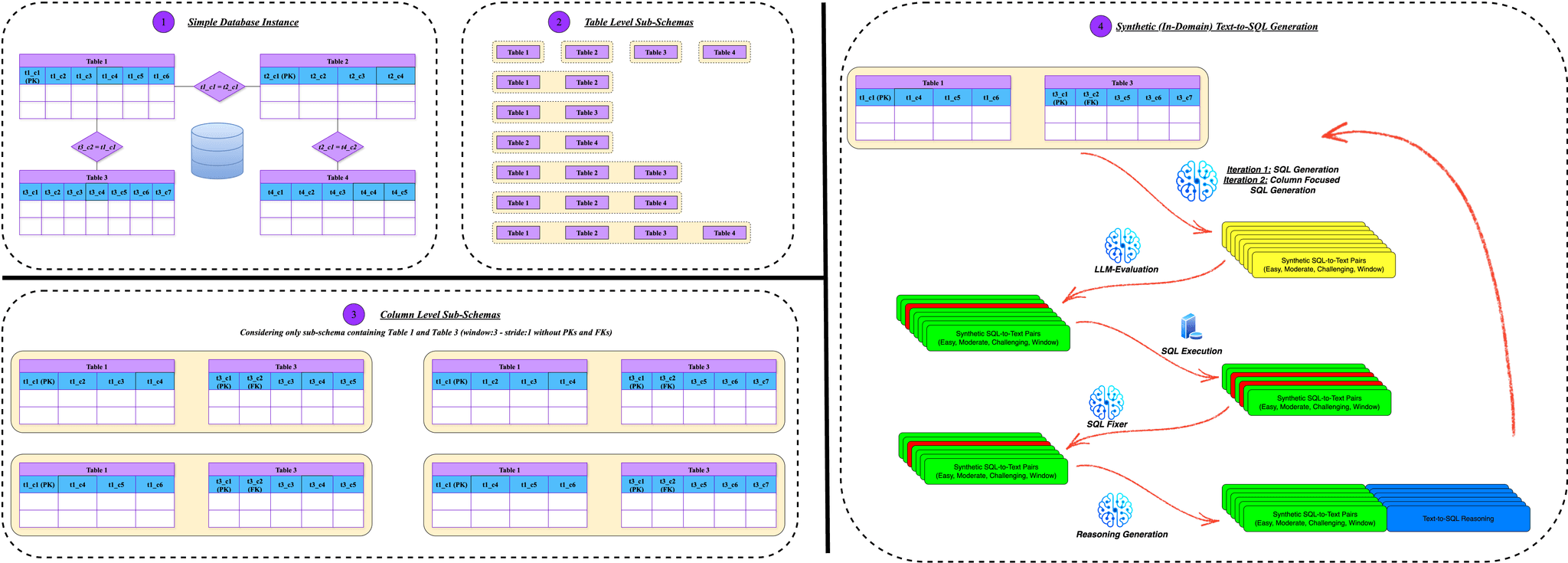
Figure 1: SING-SQL quality-aware SQL–Text generation pipeline with validation, executability checks, repair, and reasoning traces.
Main Results
Below we highlight performance on California Schools (BIRD dev subset), and on SING-SQL's synthetic California Schools Dev/Test with 8 candidate SQLs:
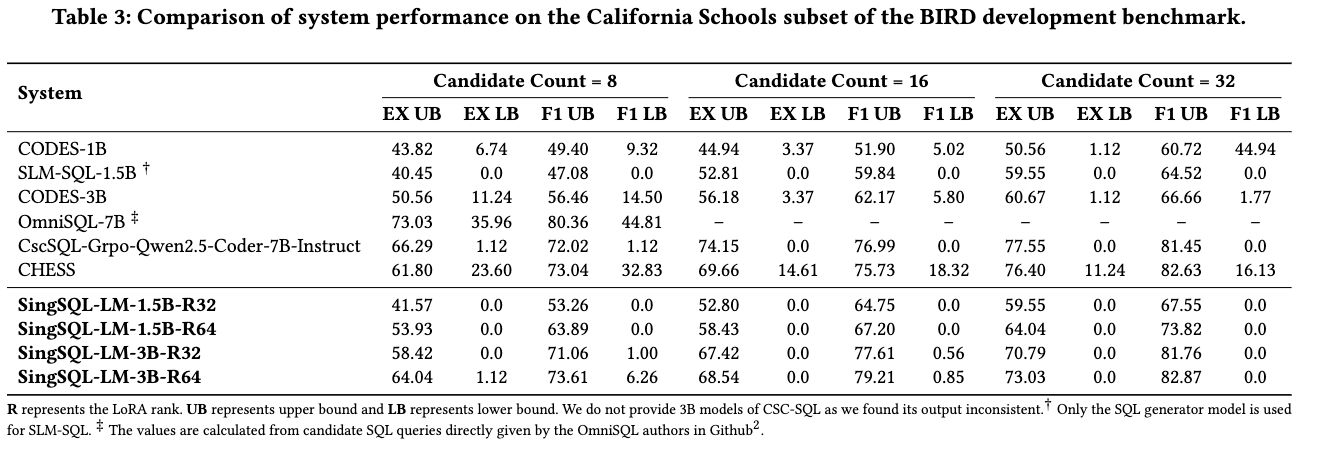
Figure 2: System comparison on California Schools subset of BIRD Dev.
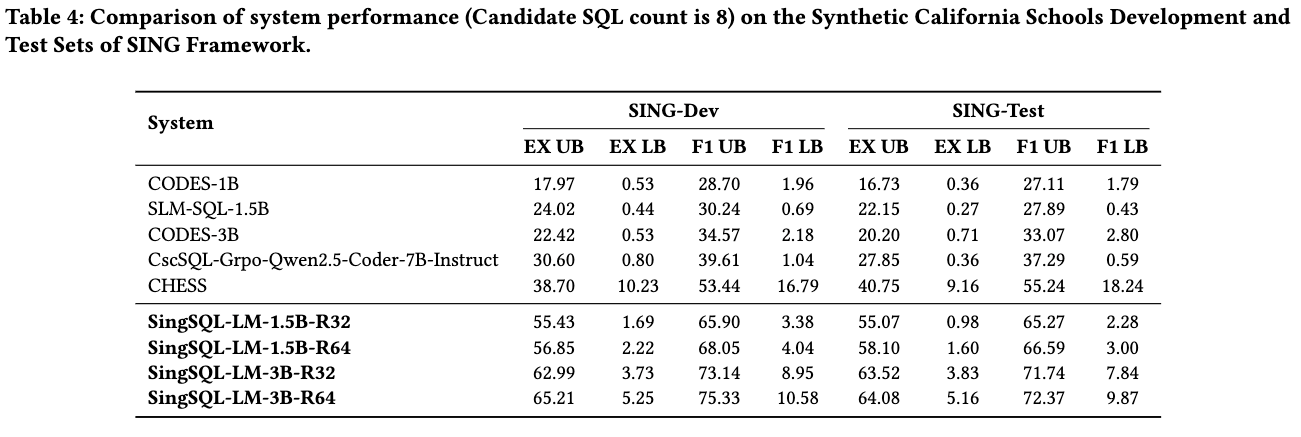
Figure 3: System comparison on SING-SQL Synthetic Dev/Test (California Schools), 8 candidate SQLs.
Data Statistics
SING-SQL produces datasets with comprehensive schema coverage and broader SQL diversity. Below, we include the question counts by difficulty level and compare join/aggregation characteristics across datasets.
Question Count Comparison
| Dataset | Overall | Simple | Moderate | Challenging | Window |
|---|---|---|---|---|---|
| BIRD-Dev | 89 | 54 | 30 | 5 | 2 |
| Synthetic Train | 34,266 | 8,685 | 8,556 | 8,046 | 9,286 |
| Synthetic Dev | 1,124 | 297 | 259 | 259 | 319 |
| Synthetic Test | 1,124 | 299 | 248 | 248 | 340 |
Join Count Comparison
The average number of joins per SQL query is a key indicator of relational reasoning complexity in Text-to-SQL datasets. As shown in Figure 4, the synthetic data generated by SING-SQL exhibits comparable or slightly higher join complexity than the BIRD development set across most difficulty levels, except for simple queries. This finding indicates that the proposed generation framework effectively integrates complex multi-table reasoning patterns into the synthetic data. Such diversity is crucial for training models that can handle realistic database interactions, where queries often require joining information from multiple related entities.
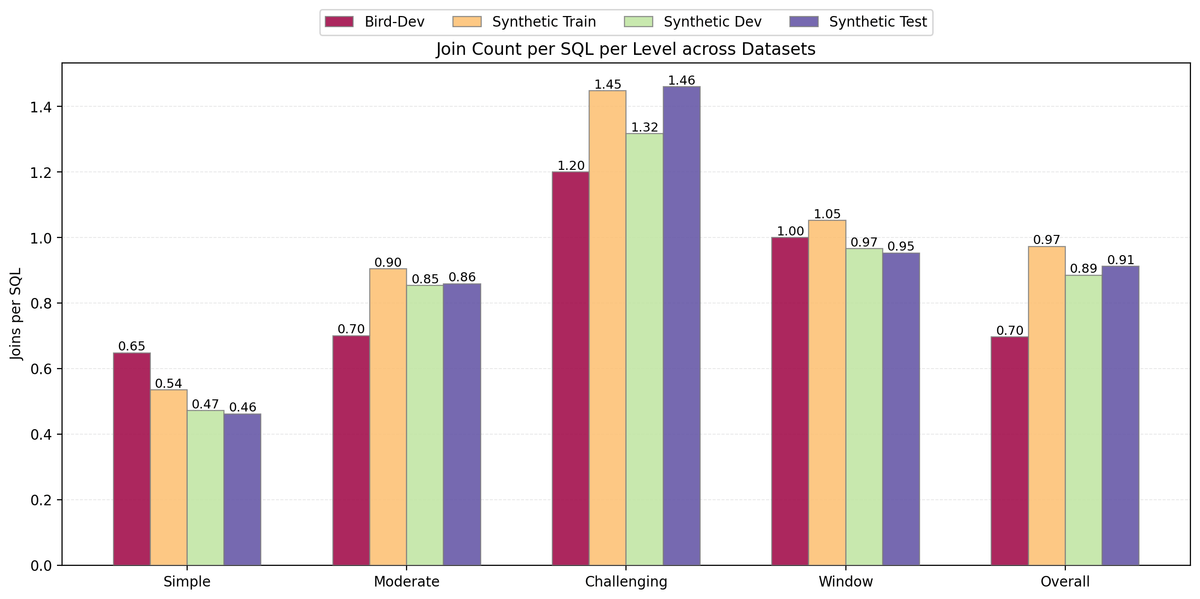
Figure 4: SING-SQL captures richer relational reasoning patterns (higher join counts) compared to BIRD.
Aggregation Comparison
Aggregation operations—such as SUM, AVG, and COUNT—reflect the analytical depth of SQL queries.Figure 5 compares the proportion of queries containing aggregation operators across datasets. While BIRD-Dev shows a higher share of aggregations in simple queries (31.48%), SING-SQL provides a more balanced and representative distribution. In particular, it introduces richer aggregation usage at moderate, challenging, and window levels, reaching up to 78.76% for challenging queries.This broader aggregation coverage ensures that the synthetic dataset captures advanced analytical reasoning patterns, helping models trained on it to better generalize to real-world data analysis scenarios where aggregations are prevalent.
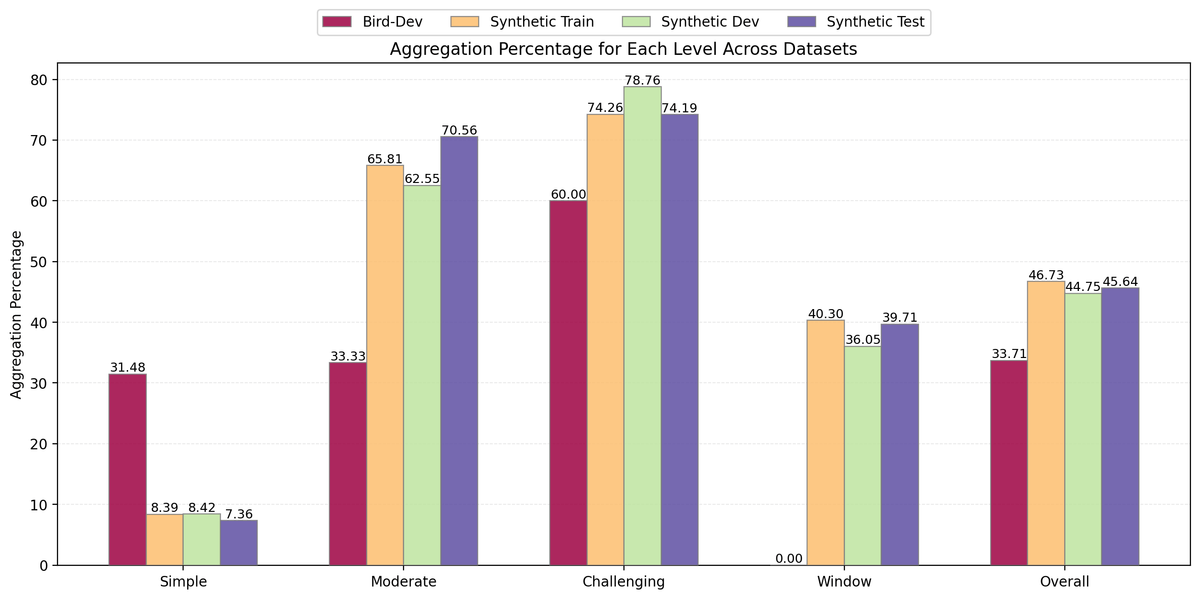
Figure 5: SING-SQL provides broader aggregation coverage, especially at moderate, challenging, and window levels.
Models
We release SingSQL-LM: compact, specialized LMs fine-tuned on the synthetic California Schools data, achieving strong in-domain performance.
| Model | Specialized DB | Base Model | Train Method | HuggingFace |
|---|---|---|---|---|
| SingSQL-LM-1.5B-R32_CS | California Schools | Qwen2.5-Coder-1.5B-Instruct | SFT | 🤗 HuggingFace |
| SingSQL-LM-1.5B-R64_CS | California Schools | Qwen2.5-Coder-1.5B-Instruct | SFT | 🤗 HuggingFace |
| SingSQL-LM-3B-R32_CS | California Schools | Qwen2.5-Coder-3B-Instruct | SFT | 🤗 HuggingFace |
| SingSQL-LM-3B-R64_CS | California Schools | Qwen2.5-Coder-3B-Instruct | SFT | 🤗 HuggingFace |
Dataset
The synthetic California Schools dataset includes train, dev, and test splits with full schema coverage and balanced complexity levels.
| Dataset | Link |
|---|---|
| California Schools | 🤗 HuggingFace |
Citation
@misc{caferoğlu2025singsqlsyntheticdatageneration,
title={SING-SQL: A Synthetic Data Generation Framework for In-Domain Text-to-SQL Translation},
author={Hasan Alp Caferoğlu and Mehmet Serhat Çelik and Özgür Ulusoy},
year={2025},
eprint={2509.25672},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.25672}
}You might also be interested in reading this: E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL

Hasan Alp Caferoglu © 2025